ChatGPT in de Klas

Artificiële intelligentie is een enorm krachtige tool. Het kan als geen ander patronen in data herkennen. Het bepaalt reeds grote delen van ons leven, zoals hoe we nieuws vergaren, eten bestellen, reizen en zelfs daten! Dat ook de talen de dans niet zouden ontspringen, stond in de sterren geschreven. Maar hoe ga je hiermee om in het onderwijs? Verbieden zoals men deed in New York? Doen alsof onze neus bloedt? Of samen met collega’s en leerlingen kritisch verkennen? Laat ons voor dat laatste kiezen, want deze technologie gaat niet meer weg. In dit artikel beschrijf ik de ‘Turing Test’ die ik uitvoerde samen met mijn leerlingen. Ik geef je ook een raamwerk en handvaten. Handvaten waarmee je meer kan halen uit jouw avonturen met AI-systemen zoals ChatGPT in jouw klas!
Achtergrond: De Turing Test

De Turing Test is een theoretische proefopstelling die werd bedacht door de Britse wiskundige Alan Turing. Hij wilde een manier bedenken om te bepalen of aan computerprogramma ‘intelligent’ is. Omdat intelligentie een zeer abstract begrip is, heeft Alan Turing het concept verengd tot het voeren van een chatgesprek. In de proefopstelling zijn drie actoren aanwezig.
Jurylid
Mens
Robot / programma
Het jurylid weet niet op voorhand wie van de deelnemers mensen zijn en wie de computers zijn. Het jurylid voert chatconversaties met de andere actoren. Nadien valt de beslissing: wie was de mens en wie de robot? Wanneer het jurylid er niet in slaagt de mens van de robot te onderscheiden, gaat Alan Turing ervan uit dat het computersysteem ‘intelligent’ is.
Er zijn natuurlijk kanttekeningen te maken bij deze proef. Het meet de vaardigheid enkel via een chatconversatie, er hangt veel af van het jurylid, het computersysteem kan gebouwd zijn om héél goed te kunnen spreken over slechts één onderwerp (zoals men deed bij Eliza en Eugene Goostman) om zo de gesprekspartner te misleiden … Ook het Chinese Room Argument van Searle tracht aan te tonen dat, hoewel de computer woorden op een scherm kan toveren, het vaak als-dan-instructies uitvoert en de taal au fond niet begrijpt. Een programma zoals ChatGPT kan je misschien even van jouw sokken blazen, maar we kunnen dus niet zeggen dat dit AI-systeem ook echt intelligent is.

Turing Test in de Klas (evaluator)
Het idee is vrij eenvoudig. De klasgroep kreeg een schrijftaak voor de kiezen. Pen een opstel over filterbubbels. Wat is het concept? Wat zijn de voordelen en nadelen? Gebruik de aangeleerde structuur uit de lessen Nederlands.
De twist zit hem in de volgende aanpassing aan deze klassieke opdracht: de groep verdeelde zich stiekem in drie. Een groep die alles zelf schrijft, een groep die 50% zelf schrijft en 50% vertrouwt op digitale tools zoals ChatGPT en tenslotte een groep die alles voor 100% laat genereren door digitale hulpmiddelen.
Leerlingen kozen zelf tot welke groep ze behoorden. De docent (=ikzelf) wist niet in welke groep welke leerling zat. Mijn doelstelling als jurylid was eenvoudig: tracht alle leerlingen te classificeren aan de hand van de door hen ingediende schrijftaken. Hiervoor mocht ook ik alle tools gebruiken die ik tot mijn beschikking had. Tools zoals mijn ervaring als docent, kennis uit voorgaande schrijftaken, plagiaatcontrole, vertaalsoftware en GPT-detectiesoftware. Dit kon je ook reeds lezen in volgend artikel van De Morgen.
Old-old school: Inhoudsevalutie
Elke docent die ooit een schrijftaak of boekbespreking opgaf zal het wel herkennen: soms duiken er woorden, begrippen of volledige zinnen op waarvan je vermoedt dat ze toch enigszins het petje van de doorsnee leerling te boven gaan. Zochten ze iets op? Kregen ze hulp van een gezinslid? Klassieke vragen die we ons eigenlijk al jaren kunnen stellen over deze evaluatiemethode.

Eli Pariser, de bedenker van de term ‘Filter Bubble’.
Zo dook in menig schrijftaak de naam op van Eli Pariser, de bedenker van het concept van de filter bubbel. Als zoveel leerlingen hem vermelden in hun opstel, leek het me wel de moeite om hen in de les even te polsen naar de kennis over hem. Of ze dit nu hadden opgevist uit Wikipedia of ChatGPT, het resultaat kan je wellicht raden.
Wanneer je een tekst van het internet plukt, of door een tool op het internet laat genereren, duiken er ook enkele stevige stellingen op, zoals dat “filter bubbels een manifeste dreiging vormen voor de sociale cohesie en onze democratie”. Stevige stelling voor een veertienjarige! Op de vraag of die dat eens mondeling kon duiden voor het bord, bleef het evenwel manifest stil.

Old school: Plagiaatcontrole en Vertaalsoftware
Tekst die geschreven wordt door een GPT-model, wordt niet geplukt van het internet. Dit maakt de methode bijzonder lastig om op te sporen door middel van de gekende plagiaatcontrole. Echter laten leerlingen zich nog steeds vangen. Soms door volledige alinea’s van een online bron te plakken tussen gegenereerde tekst.

Deze tekst werd niet gevlagd door de traditionele plagiaatcontrole. Zijn Engelstalige vertaling daarentegen wel.
Sommige leerlingen zijn inventiever. Die zoeken een online bron in een vreemde taal, vertalen deze aan de hand van Google Translate of DeepL, om deze daarna pas in te dienen. Zo zijn ze klassieke plagiaatsoftware te slim af … totdat je als docent hun tekst opnieuw vertaalt van het Nederlands naar het Engels. Oeps …
New school: GPT Inhoud
Wat modellen zoals GPT3 en ChatGPT klaarspelen doet natuurlijk dromen. Het is indrukwekkend dat negen op de tien voorbeelden die je ermee genereert best oké zijn. Enkele jaren en versies geleden waren negen op de tien voorbeelden ronduit erbarmelijk of chaotisch, met één uitblinker. Sommige gebruikers lijken uit de indrukwekkend prestatie te concluderen dat het model zaken online opzoekt terwijl het schrijft, of een berg van feiten in zijn neuraal netwerk heeft zitten. Zo werkt het niet. Het is belangrijk om leerlingen te duiden dat ChatGPT geen zoek- of feitenmachine is. Dat ze de geschreven teksten best kritisch bekijken. Neem onderstaand voorbeeld:
Filter bubbles are a phenomenon that causes people to stop seeing news stuff, but get stuck within a certain genre they like. Social media, news sites and search engines use algorithms to show users things that are likely to be very interesting. This can lead to users finding themselves in a bubble of information thatconfirms their existing beliefs and biases, rather than exposing them to a varietyof viewpoints. Filter bubbles can also have bad consequences for single peopleand much more, they cause single people and society to think less critically. Thus, they can also ensure that misinformation will be perpetuated. To combatfilter bubbles, it is important to be aware of the ways in which they can influencethe information we use. This can include actively seeking a variety of viewpoints, fact-checking information and being aware of the sources of theinformation we read.
Hier is op het eerste zicht niets verkeerd mee, maar een zinssnede valt op wanneer je (vak)kennis hebt over het onderwerp
Filter bubbles can also have bad consequences for single peopleand much more, they cause single people and society to think less critically.
Filterbubbels zouden dus voornamelijk gevaarlijk zijn voor alleenstaande mensen. Een nieuwe bewering die ik nog niet eerder las. Helaas voor de leerling in kwestie is het geen feit, maar wellicht eerder een verzinsel van de machine. Een verzinsel dat het wel zeer overtuigend bracht. We bekijken nog een tweede voorbeeld:
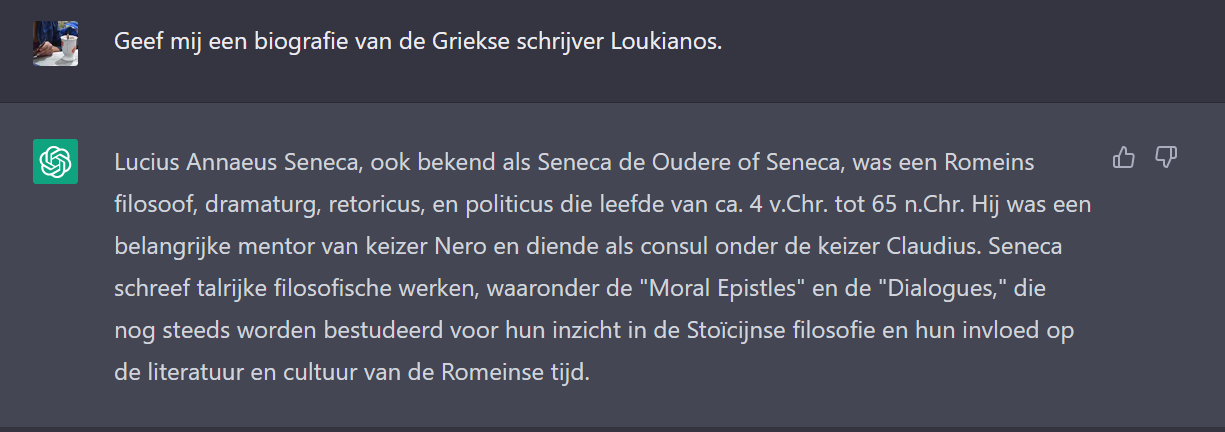
Een leuke samenvatting, alleen prik je er heel snel door. Loukianos en Seneca zijn twee verschillende figuren uit de Romeinse geschiedenis en Griekse literatuur. Maar hoe slaagt ChatGPT er dan in deze twee te verwarren? Waarom is het geen feitenmachine?
Dit komt door de manier van werken. Het systeem bekijkt tekst niet zoals wij dat doen. Het is een binaire getallenreeks waarbij het model vectoren berekent tussen woorden. Woorden die vaak samen voorkomen in diverse teksten, die hebben een verband met elkaar. Zoals het woord ‘Albert’ met ‘koning’ en op zijn beurt ‘koning’ met ‘mannelijk’. Een GPT model doet aan soort kansberekening. Heel simplistisch uitgedrukt: Het probabilistisch model berekent dus het volgende woord in de zin. Opnieuw en opnieuw. Zo maak je best overtuigende zinnen, maar wetenschap bedrijf je er niet mee.
New school: AI-modellen detecteren met AI-modellen
Naast de gekende methodes kan je ook AI-modellen inschakelen om AI-modellen op te sporen. Behoorlijk meta dus, maar hoe gaat dit in zijn werk? Online tools zoals GPTzero analyseren de gegeven tekst en berekenen, zin per zin, de complexiteit. De reden daarachter kunnen we als volgt samenvatten: wanneer mensen een tekst schrijven hanteren ze een eigen schrijfstijl. De complexiteit van woorden verschilt enorm van zin tot zin! Mensen schrijven vrij ‘bursty’. Dus met plotse toenames van moeilijkere woorden.
Dit in tegenstelling tot een GPT-model. Dat schrijft teksten die een vrij uniforme complexiteit kennen. De menselijke horten en stoten ontbreken dus! Hieronder zie je dit uitgewerkt op een grafiek. Let vooral op de Y-as die een pak lager uitvalt bij de GPT-tekst dan bij de tekst geschreven door een mens.
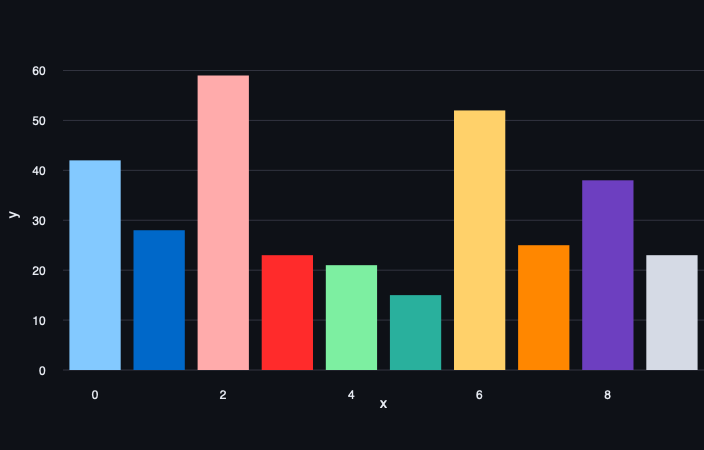
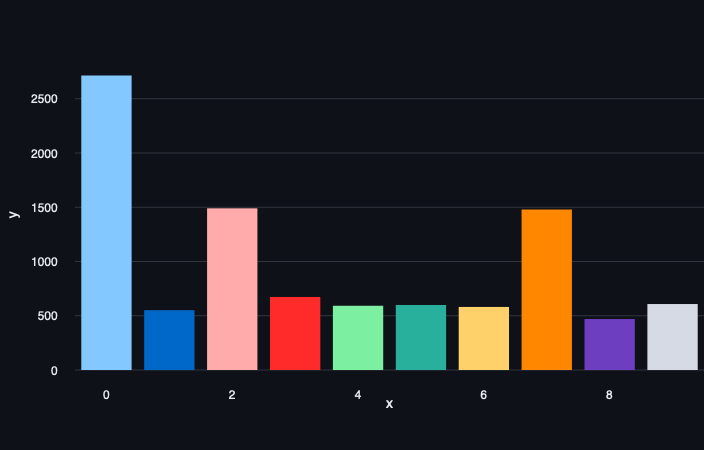
Opgelet: een GPT-detectie is niet het wondermiddel. Laat je een tekst schrijven door AI-model A om daarna te laten samenvatten door model B, dan zal zo een detectiesysteem niet meer functioneren. Ook het ingebouwde van een watermerk (waar OpenAI aan zou werken) verdwijnt wanneer robots elkaars werk parafraseren. Zoals we ook kennen uit de wereld van de valsmunterij, computervirussen of natuurlijke virussen; het zal een kat-en-muisspel blijven tussen tekstgeneratoren en detectoren.
Hoe wél aan de slag met GPT (tool)
Het mag duidelijk zijn: doen alsof onze neus bloedt of dergelijke tools verbieden zal niet werken. We kunnen er maar beter kritisch mee aan de slag. Daarvoor kan je gebruikmaken van stappenplannen zoals het KOFFIE-framework.

Net zoals elke gerenommeerde koffiebar uitbreidingen met ‘shots’ aanbiedt, kan je ook op dit KOFFIE-raamwerk uitbreiden met enkele shots!
‘Zero Shot’-Aanpak
Ten eerste hebben we de ‘zero shot’-aanpak. Een klassieker! Je geeft het AI-model een klare en duidelijke instructie. Bijvoorbeeld om een introductie te schrijven over waterschildpadden.

‘One Shot’-Aanpak
Mag het straffer? Dan is er de ‘one-shot’-aanpak. In deze aanpak omschrijf je beter waar je naartoe wil. We voegen hier een structuur aan toe over de flamingo. We willen dat het model deze structuur volgt om een introductie te pennen over onze waterschildpad. Maak het ook niet te bont in deze stap. Voeg niet teveel details toe die afwijken van de doelstelling en/of structuur. Behoud de focus!

‘Few Shot’-Aanpak
Die omschrijving en focus kunnen we op nog hoger niveau tillen met de ‘few shot’-aanpak. Geef hem meerdere voorbeelden van de gewenste structuur zoals hier met de beer en de flamingo. Maak je geen zorgen over de precieze feiten zoals de hoogte van de flamingo of wat een beer eet. In de instructie voeg je elementen toe zoals doelgroep, hoeveel lijnen, eigenschappen van het gewenste dier. Hier koos ik voor de Shoggoth. Een volledig verzonnen beest dat weggelopen is uit een verhaal van de hand van H.P. Lovecraft. Het AI-model slaagt er in om onze opgegeven eigenschappen van het beest op de juiste plaats te schrijven, volgens de door ons opgegeven structuur!

Sleutelen aan de input …
Deze KOFFIE-aanpak kunnen we illustreren aan de hand van volgend voorbeeld: je bent leerkracht klassieke talen en wil met de leerlingen een creatieve verwerking uitvoeren. Godendialogen zijn jou niet onbekend. Hierin schrijven de leerlingen een gesprek tussen twee gekozen goden. Deze gesprekken moeten natuurlijk wel enkele elementen bevatten uit de les. Leerstof uit de cultuurlessen, een stukje Oudgriekse of Latijnse taal …
Wanneer we de kladversie maken van onze godendialoog, kunnen we teruggrijpen naar bijvoorbeeld ChatGPT. We geven het AI-systeem een structuur mee, randinformatie over onze sprekers, de toon van het gesprek, het perspectief van de goden … Zo omschrijven we onze instructie, de input voor het systeem. ChatGPT zal op dit elan verder werken. Genereer zo een aantal versies. Itereer en evalueer dus! Pas jouw instructie hier en daar aan, doe dus aan finetuning, om zo betere resultaten te bekomen.


Kritisch kijken naar de output!
Ook bij moderne talen kan je tools zoals ChatGPT integreren en kan het kritisch evalueren van dergelijke AI-systemen bijdragen aan het leren. In het voorgaande voorbeeld maakten we reeds gebruik van het omschrijven, finetunen, itereren … uit het KOFFIE-model. Dit model gebruikten we om een zo goed als mogelijke output te krijgen uit het GPT-systeem door systematisch te sleutelen aan de input. Maar ook met die verbeterde output kunnen we in de klas aan de slag.
Kijk kritisch naar de tekststructuur, ook al heb je die opgegeven bij het opstellen van jouw prompt;
Houd de “feiten” van GPT tegen het licht, want ChatGPT is géén feitenmachine;
Voeg eigen vakkennis, anekdotes en verduidelijkingen toe;
Schrap de overbodige herhalingen, vreemde bokkensprongen en hallucinaties van het AI-systeem;
Stel samen met de leerlingen een evaluatiematrix op en evalueer zo samen de output van het AI-systeem!
Ik wil dit in mijn klas! Wat moet ik doen?
Wil je hier zelf mee aan de slag in jouw klaslokaal? Super! De toekomst zal steeds meer en meer digitaal zijn. Een toekomst waar artificiële intelligentie een heel belangrijke rol in zal spelen, in allerlei facetten van ons leven. Dat we jongeren hierop moeten voorbereiden en motiveren, spreekt voor zich. Mocht je na het lezen van bovenstaand artikel nog enkele vragen hebben, dan wil ik jou daar gerust bij helpen! Via de knoppen hieronder kan je mij een bericht sturen of informatie krijgen over een nascholing of workshop. Ik antwoord veelal binnen de 48 uur!